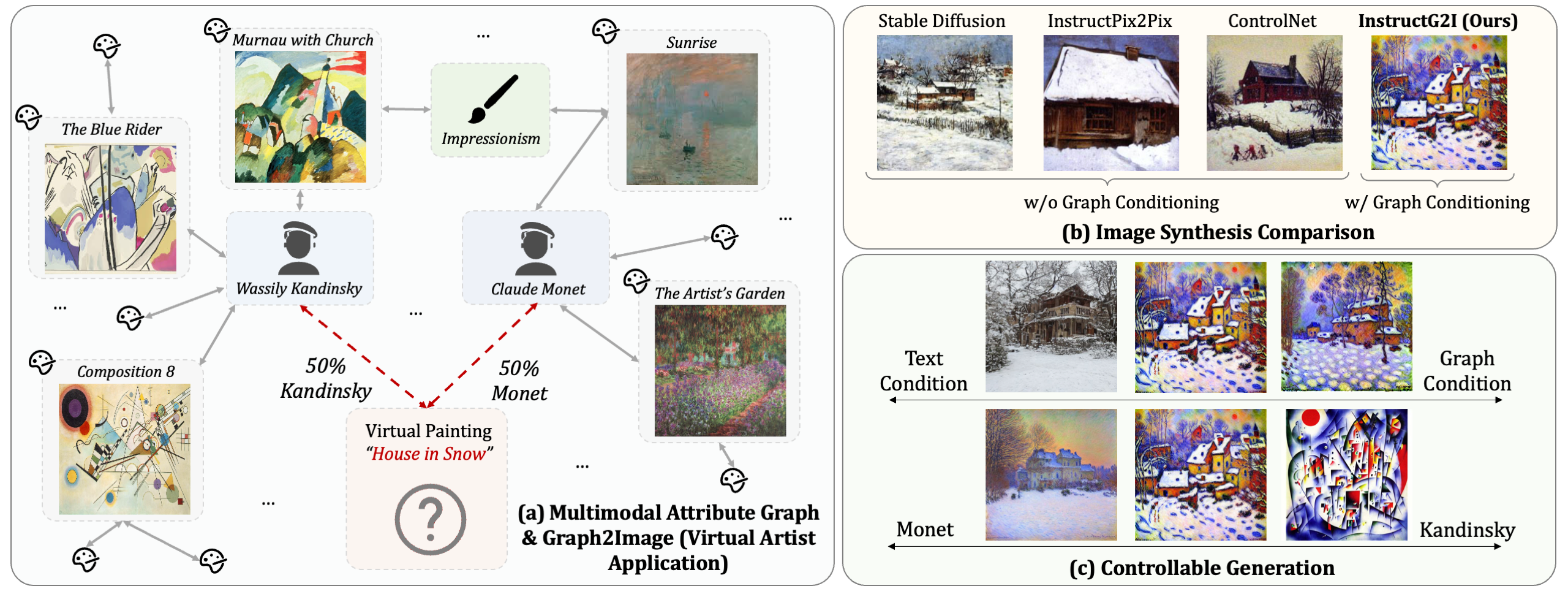
In this paper, we approach an overlooked yet critical task Graph2Image: generating images from multimodal attributed graphs (MMAGs). This task poses significant challenges due to the explosion in graph size, dependencies among graph entities, and the need for controllability in graph conditions. To address these challenges, we propose a graph context-conditioned diffusion model called InstructG2I. InstructG2I first exploits the graph structure and multimodal information to conduct informative neighbor sampling by combining personalized page rank and re-ranking based on vision-language features. Then, a Graph-QFormer encoder adaptively encodes the graph nodes into an auxiliary set of graph prompts to guide the denoising process of diffusion. Finally, we propose graph classifier-free guidance, enabling controllable generation by varying the strength of graph guidance and multiple connected edges to a node. Extensive experiments conducted on three datasets from different domains demonstrate the effectiveness and controllability of our approach.
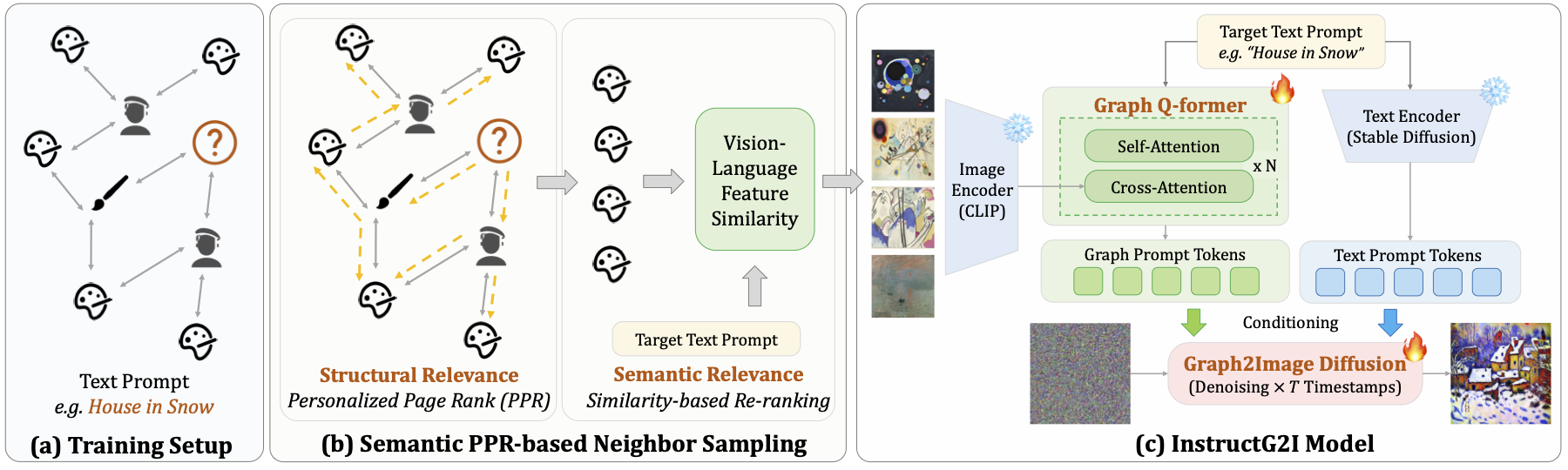
In our task, the score network \(\hat{\epsilon}_\theta(\mathbf{z}_t, c_G, c_T)\) is conditioned on both text \(c_T=d_i\) and the graph condition \(c_G\). We compose the score estimates from these two conditions and introduce two guidance scales, \(s_T\) and \(s_G\), to control the contribution strength of \(c_T\) and \(c_G\) to the generated samples respectively. Our modified score estimation function is: \[ \hat{\epsilon}_\theta(\mathbf{z}_t, c_G, c_T) = {\epsilon}_\theta(\mathbf{z}_t, \varnothing, \varnothing) + s_T \cdot ({\epsilon}_\theta(\mathbf{z}_t, \varnothing, c_T) - {\epsilon}_\theta(\mathbf{z}_t, \varnothing, \varnothing)) \notag \\ + s_G \cdot ({\epsilon}_\theta(\mathbf{z}_t, c_G, c_T) - {\epsilon}_\theta(\mathbf{z}_t, \varnothing, c_T)).\label{eq:cfg1} \] For cases requiring fine-grained control over multiple graph conditions (i.e., different edges), we extend the formula as follows: \[ \hat{\epsilon}_\theta(\mathbf{z}_t, c_G, c_T) = {\epsilon}_\theta(\mathbf{z}_t, \varnothing, \varnothing) + s_T \cdot ({\epsilon}_\theta(\mathbf{z}_t, \varnothing, c_T) - {\epsilon}_\theta(\mathbf{z}_t, \varnothing, \varnothing)) \notag \\ + \sum s^{(k)}_G \cdot ({\epsilon}_\theta(\mathbf{z}_t, c^{(k)}_G, c_T) - {\epsilon}_\theta(\mathbf{z}_t, \varnothing, c_T)),\label{eq:cfg2} \] where \(c^{(k)}_G\) is the \(k\)-th graph condition. For example, to create an artwork that combines the styles of Monet and Van Gogh, the neighboring artworks by Monet and Van Gogh on the graph would be \(c^{(1)}_G\) and \(c^{(2)}_G\), respectively.




@article{jin2024instructg2i,
title={InstructG2I: Synthesizing Images from Multimodal Attributed Graphs},
author={Jin, Bowen and Pang, Ziqi and Guo, Bingjun and Wang, Yu-Xiong and You, Jiaxuan and Han, Jiawei},
journal={arXiv preprint arXiv:2410.07157},
year={2024}
}